JYSK er en af verdens største home furnishing retailers med et sortiment, der tæller tusindvis af produkter, og webshops i 50 lande. Ambitionen er at være det foretrukne valg, når kunder søger skandinavisk design til en god pris. For at det lykkes, skal JYSK være synlig der, hvor kunderne søger og shopper – og det kræver et konstant arbejde med optimering af produktdata.
JYSK havde et rigt datafundament og dermed et stort potentiale for at tage deres search-aktiviteter til næste niveau. Men netop den store mængde data var både potentialet og udfordringen:
Produktdata var vokset organisk over mange år, formet af over 80 forskellige skabeloner og udviklet uafhængigt på tværs af markeder og teams; en naturlig følge af JYSKs stærke rødder i fysisk retail.
Det betød, at værdifulde produktdata som dimensioner, materialer og funktionalitet allerede fandtes i systemet, men de var ikke struktureret, så de kunne aktiveres effektivt på tværs af platforme. Produkter blev derfor ikke præsenteret optimalt i de kanaler, hvor kunderne søgte og købte, og dermed missede JYSK potentielle salg. Det var et kritisk problem set i lyset af, at Google er blevet verdens største shoppingvindue, og konkurrencen fra digitale pure players er benhård.
Samtidig var JYSK optimeret til stabil drift, ikke hurtig test og iteration. Forbedringer krævede koordinering på tværs af marketing, IT og markeder, og effekten kunne først måles efter global implementering.
Problemet var derfor todelt: 1) Data var tilgængelige, men ikke aktiverede, og 2) organisationen manglede en skalerbar måde at optimere produktdata.
Der var brug for en model, hvor JYSK kunne arbejde systematisk med produktdata som en vækstdriver: teste, lære og skalere – hurtigt og målbart.
Løsningen tog direkte afsæt i udfordringen: at skabe en effektiv og skalerbar måde at strukturere eksisterende produktdata på og samtidig sikre løbende optimering.
JYSK og s360 udviklede derfor en løsning i tre trin:
1. FRA MANUEL TIL AUTOMATISK PROCES
Vi gennemførte en analyse af JYSKs produktfeeds for at identificere mangler og inkonsistens på tværs af attributter som materiale, farve, mønster og størrelse.
For at skalere arbejdet anvendte vi s360s proprietære AI-værktøj Quantum Feed Engine (QFE).
QFE analyserer eksisterende produktdata og -billeder og bruger dem til automatisk at berige og standardisere produktinformationer på tværs af hele kataloget i en skala, der aldrig ville have været muligt manuelt.
Et produkt, der tidligere kun var beskrevet med få generiske attributter, kunne nu udvides med langt flere detaljer som dimensioner, funktionelle egenskaber, materialetyper og anvendelse.
Det gav både platforme og kunder en mere fyldestgørende beskrivelse af produktet og et stærkere beslutningsgrundlag - uden at processen krævede nogen form for manuel håndtering.
2. TEST FØR SKALERING
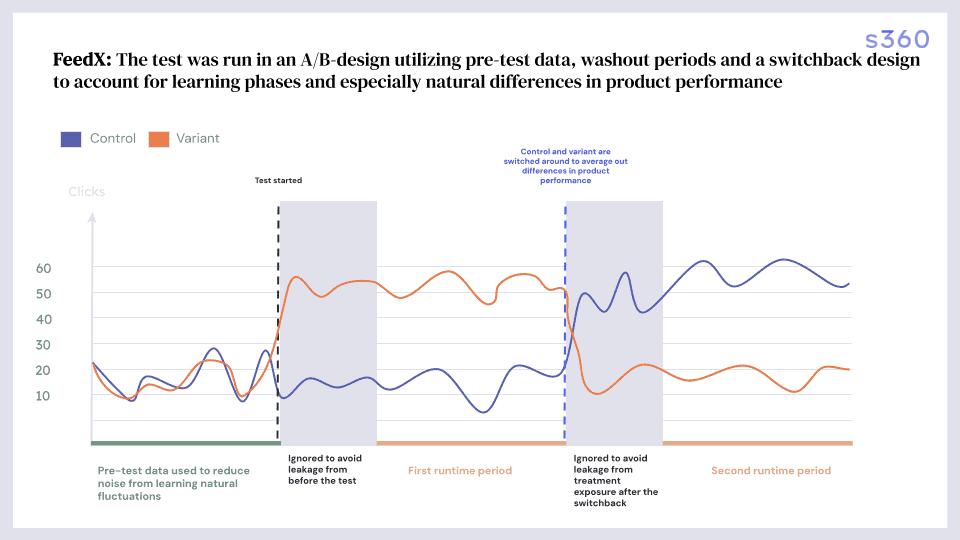
Med JYSKs enorme produktsortiment kan selv små feedoptimeringer have stor effekt; både i positiv og negativ forstand. Vi etablerede derfor et struktureret test-setup for at validere alle ændringer før skalering.
Hver optimering blev formuleret som en hypotese og testet kontrolleret i udvalgte markeder med kontrol- og variantgrupper. Eksempelvis blev effekten af optimerede titler, kundeanmeldelser og flere produktattributter analyseret isoleret. Halvvejs blev grupperne byttet for at sikre valide resultater.
Kun resultater med mindst 98% statistisk signifikans blev erklæret vindende initiativer og blev implementeret globalt.
Et af de vindende initiativer var kundeanmeldelser. Dataene fandtes allerede i JYSKs systemer, men var ikke struktureret til at blive vist i Shopping Ads. En mindre teknisk justering gjorde anmeldelserne synlige og øgede klikraten med 3,22%. Det er et godt eksempel på, hvor stor effekt små optimeringer kan have.
60% af alle tests endte med at blive implementeret globalt. De resterende 40% skabte værdifulde indsigter om, hvad der ikke gav mening at prioritere.
3. FRA TESTS TIL SKALERBAR MODEL
For at sikre varig effekt dokumenterede vi alle tests i et fælles learning repository med standardiserede processer, skabeloner til testdesign og rapportering.
Det gav JYSKs teams på tværs af markeder et fælles udgangspunkt for at arbejde med optimering af produktfeedet og gjorde det muligt at implementere forbedringer hurtigt og ensartet.
Ved hjælp af en struktureret tilgang til dataanvendelse og kreativ AI-baseret teknologi skabte vi et fundament, der gør JYSK agil i optimering af produktfeeds.
Efter et års systematisk arbejde med databerigelse, tests og skalering fra december 2024 til december 2025 er effekten tydelig. De datadrevne optimeringer estimeres at generere:
• 20 millioner inkrementelle klik årligt
• 293 mio. DKK i årligt salgsopløft på tværs af 25 markeder
• Alt sammen opnået uden øget mediespend
Resultaterne er en direkte effekt af den øgede datakvalitet. Vi har hverken hævet budgetter eller sat nye kampagner i søen. Vi har anvendt AI-teknologi til at strukturere eksisterende produktdata og omsat skjult værdi til konkret vækst.
Ved at strukturere og berige eksisterende produktdata er JYSK i dag langt bedre positioneret i de kanaler, hvor kunderne søger og shopper. Produkterne vises mere præcist, mere relevant og i flere sammenhænge – hvilket direkte øger både synlighed, performance og konkurrencedygtighed.
Samtidig er der sket en organisatorisk udvikling i måden, JYSK arbejder med data på:
Produktdata er i dag standardiserede og skalerbare på tværs af markeder. Optimeringer kan testes, valideres og skaleres løbende, uden tunge processer. Beslutninger kan træffes på baggrund af konkrete testresultater.
Det betyder, at JYSK ikke blot har forbedret deres nuværende performance, men også etableret et setup, der løbende kan udvikle og optimere deres digitale synlighed i takt med markedet.
Det er en case, der demonstrerer, hvordan data, metode og AI-innovation kan konverteres til forretningsvækst. JYSK og s360 har gjort produktdata til en kontinuerlig vækstmotor med dokumenteret effekt globalt.